|
Stan Szymanowicz I am a PhD student at VGG group at University of Oxford, where I work on Computer Vision and Machine Learning with Andrea Vedaldi and Christian Rupprecht. I spent the summer 2024 interning at Google San Francisco, continuing in London until April 2025. Before my PhD, I worked at Microsoft Mixed Reality Lab (2021-2022) in Cambridge and received an MEng with Distinction from the University of Cambridge (2017-2021). Email / Google Scholar / Twitter / Github |

|
ResearchI am interested in generative modelling of the 3D world. |

|
LagerNVS: Latent Geometry for Fully Neural Real-Time Novel View Synthesis
Stanislaw Szymanowicz, Minghao Chen, Jianyuan Wang, Christian Rupprecht, Andrea Vedaldi CVPR, 2026 code / models / project page / arXiv Real-time, generalizable novel view synthesis enabled by 3D biases without explicit 3D representations. |

|
Bolt3D: Generating 3D Scenes in Seconds
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, Aleksander Holynski, Ricardo Martin-Brualla, Jonathan T. Barron, Philipp Henzler ICCV, 2025 project page, with an interactive viewer in Chrome / arXiv Bolt3D allows feed-forward 3D scene generation in 6.25s on a single GPU. Our latent diffusion model directly outputs 3D Gaussians, and is trained on a large-scale dataset of reconstructed 3D scenes. |

|
Flash3D: Feed-Forward Generalisable Scene Reconstruction from a Single Image
Stanislaw Szymanowicz*, Eldar Insafutdinov*, Chuanxia Zheng*, Dylan Campbell, Joao Henriques, Christian Rupprecht, Andrea Vedaldi 3DV, 2025 code / project page / arXiv We show that leveraging a Monocular Depth Estimator and a Layered Representation allows building generalizable and efficient 3D scene reconstructors. |

|
Splatter Image: Ultra-Fast Single-View 3D Reconstruction
Stanislaw Szymanowicz, Chrisitian Rupprecht, Andrea Vedaldi CVPR, 2024 code / project page / demo / arXiv We design a fast (38FPS), simple, 2D network for single-view 3D reconstruction that represents shapes with 3D Gaussians. As a result, it can leverage Gaussian Splatting for rendering (588FPS), achieves state-of-the-art quality in several cases and is trains on just a single GPU. |

|
Viewset Diffusion: (0-)Image-Conditioned 3D Generation from 2D Data
Stanislaw Szymanowicz, Chrisitian Rupprecht, Andrea Vedaldi ICCV, 2023 code / project page / arXiv / paper Novel formulation of the denoising function in Diffusion Models lets us train 3D generative models from 2D data only. Our models can perform both few-view 3D reconstruction and 3D generation. |
|
|
Photo-realistic 360◦ Head Avatars in the Wild
Stanislaw Szymanowicz, Virginia Estellers, Tadas Baltrusaitis, Matthew Johnson ECCV Workshop on Computer Vision for Metaverse, 2022 arXiv We unlock training NeRFs of 360◦ human heads from mobile phone captures. Synthetically-trained face keypoint detector allows to get a rough camera pose estimate which is then refined in the optimization process. |
|
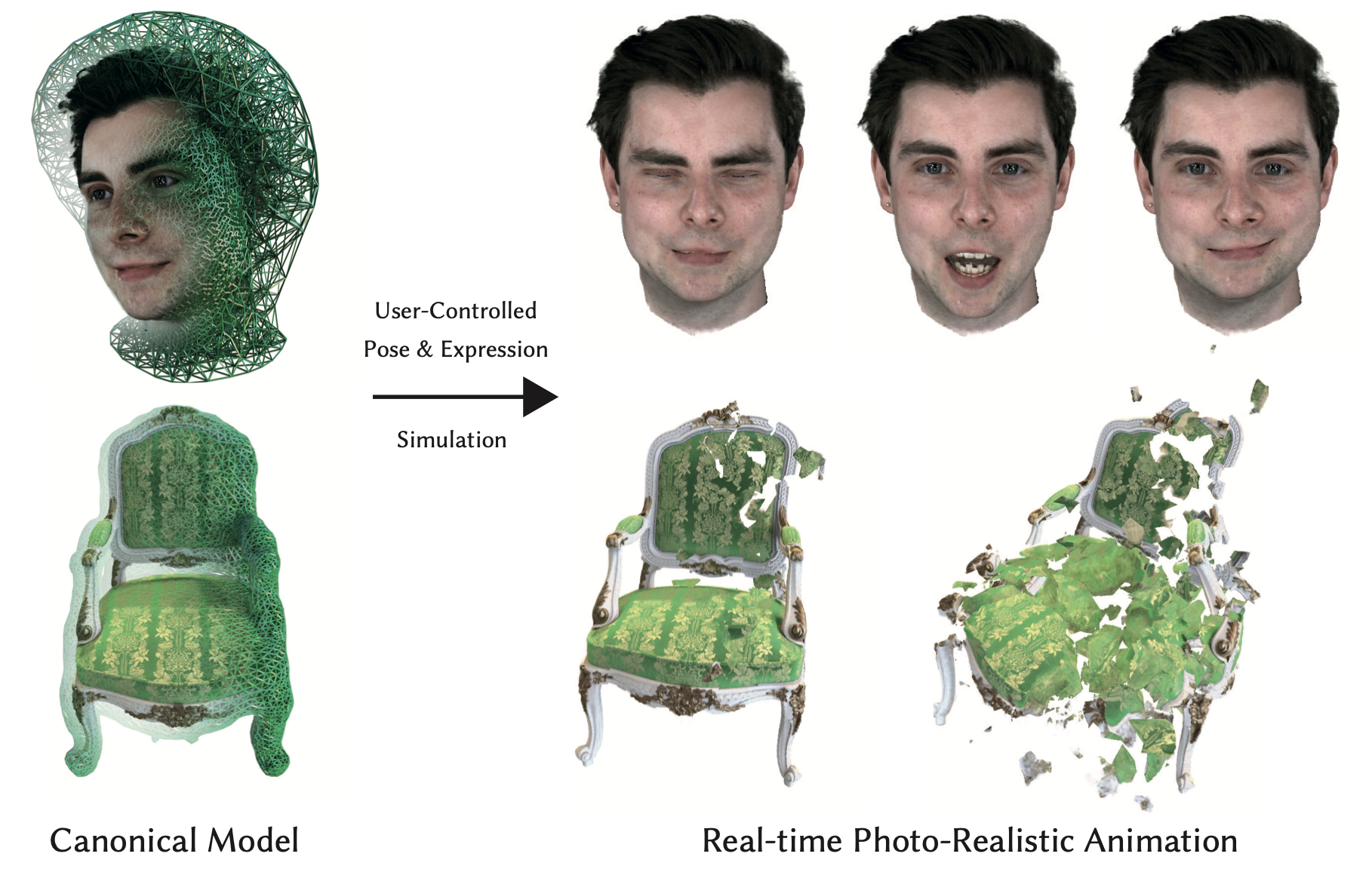
VolTeMorph: Realtime, Controllable and Generalisable Animation of Volumetric Representations
Stephan Garbin*, Marek Kowalski*, Virginia Estellers*, Stanislaw Szymanowicz*, Shideh Rezaeifar, Jingjing Shen, Matthew Johnson, Julien Valentin arXiv, 2022 arXiv We can controllably animate Neural Radiance Fields by deforming tetrahedral cages. Tetrahedral connectivity allows us to run the animations in real-time. |

|
Discrete neural representations for explainable anomaly detection
Stanislaw Szymanowicz, James Charles, Roberto Cipolla WACV, 2022 project page / video / arXiv We introduce an architecture for improved explainability of anomaly detection in CCTV videos. |

|
X-MAN: Explaining multiple sources of anomalies in video
Stanislaw Szymanowicz, James Charles, Roberto Cipolla CVPR Workshop on Fair and Trusted Computer Vision, 2021 project page / demo video / paper We introduce a dataset and a method for detecting and explaining anomalies in CCTV videos. |
|
Thank you to Jon Barron for the source code for the website! |